There are no good philosophers of software.
There is some good philosophy inspired by software, or on the society created by software, or on how software changes the way we think.
There is no good philosopher of software construction.
That is the provocation I threw out on Twitter in response to Hillel Wayne‘s excellent prompt, two and a bit months ago.
The provocation got some attention, and what I was hoping for even more, some excellent responses, and suggestions for new things to read. It definitely highlighted some gaps on my side. But I honestly do feel there is a hole where the philosophy of software construction should be, and that the world feels this lack keenly, especially when we consider how ubiquitous software is in sensing, controlling, and mediating that world. So I’ve recapped the original thread below, as well as some good responses to the original prompt, especially ones that point in interesting new directions.
Deleuze and Guattari describe philosophy, as distinct from art and science, as the creation of concepts.

Hillel (the OP) thinks deeply and reads broadly on software construction. I would argue that there is no writer creating deep concepts for software construction as part of a larger project.
This isn’t really an anomaly. It’s because there is very little philosophy of engineering.
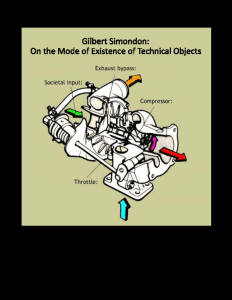
The two really compelling books I would put in that category are Simondon’s On the Mode of Existence of Technical Objects and Wimsatt’s Re-Engineering Philosophy For Limited Beings. Simondon only had readily available English translations relatively recently, and should be read more. This book analyses how machines improve through being recomposed in their broader context (milieu). A key concept is concretisation: replacing theory with realized parts. Wimsatt is great and you don’t have the translation excuse. He also touches on software and programming, but is not really a philosopher of software. A key concept is “ontological slime”, spaces of symbolic irregularity which have no simple organizing theory.
Otherwise, there is philosophy which theorises software and uses its concepts to describe the world – such as Sadie Plant’s Zeroes and Ones, or Benjamin Bratton’s The Stack.
There is writing which gives a sense of what computation is – such as Hofstader’s Gödel, Escher, Bach. “Strange loop” counts as the creation of a concept, so it is philosophy, or maybe theory-fiction. Laurel’s Computers as Theatre also fits here.
There is philosophy on the ethics of software, which is mainly about telling programmers what to do. This is fine so far as it goes, but not really a philosophy of software, and often not very software-specific.
There is philosophy written by mathematicians and computer scientists on the impact of computing: Turing’s paper Computing Machinery and Intelligence, and many such contributions since.
There is philosophy which sees computation as fundamental to the universe and intelligence, like Reza Negarestani’s Intelligence and Spirit.
There is philosophy which uses computation, like the analytical philosophers who write Haskell and develop theory provers like Coq, or Peli Grietzer’s Theory of Vibe.
There are software design guides which attempt to go up a level of abstraction, like Ousterhout’s A Philosophy of Software Design.
Then there are drive bys and fragments. Yuk Hui’s On The Existence of Digital Objects builds on Simondon and is probably in the neighbourhood.
James Noble’s classic talk on Post-Postmodern Programming:
Some work on computational materials by Paul Dourish, like The Stuff of Bits, and blog posts on the topic by Harrison Ainsworth and Carlo Pescio.
Abramsky’s paper Two Questions on Computation. Some essays in the Matthew Fuller edited Software Studies: A Lexicon. Other uncollected ramblings on blogs and Twitter.
But there is no coherent project created by a philosopher of software, such that I could point to a book, or ongoing intellectual project, and say “start there, and see your everyday world of software construction differently”.
The Project
A number of people pointed out that this long list of negations didn’t include any positive statement of what I was looking for. Let me fix that. A good philosopher of software would have:
- A coherent project
- That is insightful on the machinic internals of software
- In communication with philosophy, and
- That recognises software design as a social and cognitive act.
Hopefully that explains why I left your favourite thinker out. At least for some of you.
Misses
There are a couple of big misses I made in this informal survey of software-adjacent philosophy. There are some other things I deliberately excluded. And there were things I never heard of, and am now keen to read.
I got mostly software people in my replies, and a number of them brought up William Kent’s Data and Reality. I have read it, I think after Hillel’s enthusiastic advocacy for it in his newsletter. ((Personally I thought it was ok but not mindblowing. However, I listened to it on audiobook, which is definitely the wrong format for it, and in one of the late, mutilated editions.)) I would place it as a book in the Philosophy of Information, albeit one not really in communication with philosophy more broadly. The Philosophy of Information is definitely a thing in philosophy more broadly, one most associated with the contemporary Oxford philosopher Luciano Floridi. You can get an overview from his paper What Is The Philosophy of Information? Floridi has written a textbook on the topic, and there’s also a free textbook by Allo et al, which is especially great if you’re poor or dabbling.
I think there’s a lot that software people can learn from pretty much anything in my list, and the Philosophy of Information does shed light on software, but it only rarely addresses point (2) in my criteria: it does not give insights into the machine internals of software. Some of it is tantalizingly close, though, like Andrew Iliadis’ paper on Informational Ontology: The Meaning of Gilbert Simondon’s Concept of Individuation.
I also should have mentioned the Commission on the History and Philosophy of Computing. Though it isn’t really a single coherent intellectual project in the sense I mean above, it is an excellent organisation, and the thinking that comes out of this stream is most reliably both in communication with philosophy and insightful about the machine internals of software. This paper by Petrovic and Jakubovic, on using Commodore64 BASIC as a source of alternative computing paradigms, gives a flavour of it.
It wasn’t mentioned in the thread or the responses, but I’ve recently been enjoying Brian Marick’s Oddly Influenced podcast, which takes a critical and constructive look at ideas from the philosophy of science, and how they can be related to software. Often, given his history (he is that Brian Marick), he’s reflecting on things like why Test Driven Development “failed” (as in, didn’t take over the world in its radical form), or how the meaning of Agile has morphed into a loose synonym of “software project management”. That makes it sound like just a vehicle for airing old grievances: it’s very far from that, and always constructive, thoughtful, and ranges across many interesting philosophical ideas.
I mentioned Media Theory thinkers via Software Studies (which even includes Kittler), but it’s worth noting that media theorists have been thinking about software quite seriously, and there is some useful dialogue between software construction and design theory, usually restricted to the context of user interfaces. Wendy Chun’s Programmed Visions and Lev Manovich’s Software Takes Command are good examples. I first read Simondon because Manovich recommended it in an interview I no longer have to hand. And other people gave Kittler’s There Is No Software paper the name check it deserves.
Others pointed out that the Stanford Encyclopedia of Philosophy is rigorous, free, and has an article on the Philosophy of Computer Science.
Glorious Discoveries
The discussion unearthed some books and papers that look pretty great, but I hadn’t even heard of, let alone read.
- Kumiko Tanaka-Ishii – Semantics of Programming
- Federica Frabetti – Software Theory: A Cultural and Philosophical Study
- M. Beatrice Fazi – Contingent Computation: Abstraction, Experience, and Indeterminacy in Computational Aesthetics
- Reilly – The Philosophy of Residuality Theory
And a suggested side-quest from philosophy of engineering
- Walter G. Vincenti – What Engineers Know and How They Know It: Analytical Studies from Aeronautical History
A Conciliatory Postscript
We can imagine both a broad and a narrow definition of the Philosophy of Software. In the broad definition, most things in this post would be included. And yes, academics, if there were a hypothetical undergraduate subject on the philosophy of software, it would probably be best to use the broad definition, and expose young developers to a broad collection of ideas about the way software works in the world. So I am not completely sincere in my provocation, but I’m not utterly insincere either.
There are delicate and intimate connections between software construction and philosophy. Consider the tortured, necessary relationship that both philosophers and programmers have with names, with intuition, or with causality. The possibility of exploring these connections, and inventing new concepts, gets swamped. It gets swamped by illiteracy and thinkpiecery on the software side, and by mechanical ignorance on the philosophy side. The narrow definition of the philosophy of software, and the recognition that there is no coherent philosophy of software construction, brings it back into view.
