Sometimes he accompanied her on her errands in the city, where everything had to be carried out in the utmost hurry. Then she would almost run to the next subway station, Karl with her bag in his hand, the journey went by in a flash, as if the train were being carried away without any resistance, already they were getting off, clattering up the stairs instead of waiting for the elevator that was too slow for them, the large squares from which the streets flowed out in a starburst emerged and brought a tumult of streamed lines of traffic from all sides, but Karl and Therese hurried, tightly together, to the different offices, cleaners, warehouses and stores which weren’t easy to contact by telephone in order to make orders or complaints, generally trivial things.
– Kafka, Amerika, Hofman trans.
“No one is better than Kafka at differentiating the two axes of the assemblage and making them function together,” say Deleuze and Guattari, and though they are referring to the Czech writer, it applies quite well to the open source distributed message queue too, even though the quote was written thirty years before its invention. Kafka in either form effects both decoupling of components and a disintegration of content. Models, formats and codes are first broken down, then made available to be reassembled in other ways.
I admit that when I first heard of it, naming an information processing system after a writer famous for depictions of absurd, violent and impenetrable bureaucracy did strike me as bold. It evokes The Departure (Der Aufbruch) as router documentation, or An Imperial Message (Eine kaiserliche Botschaft) as a Service Level Agreement. Perhaps we can think of the system developers as finally addressing Franz’s eloquent, frustrated, bug reports. Jay Kreps, the namer of Apache Kafka and one of the co-creators (with Narkhede and Rao), simply explains that he wanted his high performance message queue to be good at writing, so he named it after a favourite prolific writer. Fortunately complete publication and reading doesn’t also require the process dying of tuberculosis, followed by a decades-long legal case. Even if Kreps did have a deeper correspondence in mind, if I were forced to explain the name all the time, I might just smile and point at my Franz fridge magnet too.
The D/G quote is from the Postulates of Linguistics chapter, concerned with the way meaning is imposed on communicating agents and their intertwining systems.
On a first, horizontal, axis, an assemblage comprises two segments, one of content, one of expression. On the one hand it is a machinic assemblage of bodies, of actions and passions, an intermingling of bodies reacting to one another; on the other hand it is a collective assemblage of enunciation, of acts and statements, of incorporeal transformations attributed to bodies. Then on a vertical axis, the assemblage has both territorial sides, or reterritorialized sides, which stabilize it, and cutting edges of deterritorialization, which carry it away. No one is better than Kafka at differentiating the two axes of the assemblage and making them function together.
– Deleuze and Guattari, November 30, 1923: Postulates of Linguistics, A Thousand Plateaus
Deleuze and Guattari are secret pomo management consultants at heart, and as their dutiful intern I have accordingly expressed the great men’s vision as an Ansoff Matrix slide for distribution to valued stakeholders.

Compare this Jay Kreps slide from Strange Loop 2015, itself entirely representative of a million whiteboard sketches accompanying middleware everywhere:

For middleware, what D/G call the cutting edges of deterritorialization, we might call a payload codec. The data structure used within the producing process is disassembled, scrambled into a bucket of bytes, then carried away along a line of flight – in this case a Kafka topic. A Kafka topic is a transactional log, a persistent multi-reader queue where the removal policy is decoupled from reader delivery, and retention is instead controlled by time or storage space windows. (Blockchains are public transaction logs optimised for distributed consensus and no retention limit. Hence their inherent parliamentary slowness.) The consumer then uses its own codec to reterritorialize the data – making it intelligible according to its own data model, and within its own process boundary. Though nowadays the class signature of the messages may match (say both sides use the JVM and import the definition from the same library), at a bare minimum the relationship of those messages to other objects and functions within the process differs.
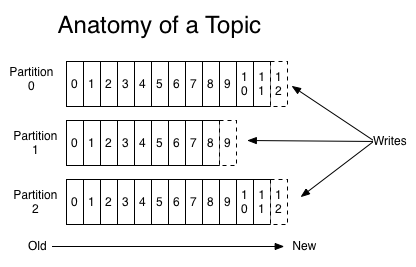
In Anti-Oedipus, D/G call reading a text “productive use of the literary machine”, and it’s along those lines that the quote continues:
No one is better than Kafka at differentiating the two axes of the assemblage and making them function together. On the one hand, the ship-machine, the hotel-machine, the circus-machine, the castle-machine, the court-machine, each with its own intermingled pieces, gears, processes, and bodies contained in one another or bursting out of containment (see the head bursting through the roof). On the other hand, the regime of signs or of enunciation: each regime with its incorporeal transformation, acts, death sentences and judgements, proceedings, “law”. […] On the second axis, what is compared or combined of the two aspects, what always inserts one into the other, are the sequenced or conjugated degrees of deterritorialization, and the operations of reterritorialization that stabilize the aggregate at a given moment. K., the K.-function, designates the line of flight or deterritorialization that carries away all of the assemblages but also undergoes all kinds of reterritorializations and redundancies – redundancies of childhood, village life, bureaucracy, etc.
– Deleuze and Guattari, ATP ibid.
Cataloguing these correspondences between D/G’s description of Kafka and the software that bears his name is not intended to ignore that their contact is a kind of iconographic car accident. Kafka is a famous, compelling writer, and frequent cultural reference point, after all. The collision of names reveals structural similarities that are usually hidden.
In the Kreps talk above, titled in Deleuzian fashion “Apache Kafka and the Next 700 Stream Processing Systems”, he also introduces a stream processing API to unify the treatment of streams and tables. The team saw this as crucial to Kafka’s identity as a streaming platform rather than just a queue, and delayed calling Kafka 1.0 for years, until this component was ready. Nomadic messages escape through the smooth stream space, before capture and transformation in striated tablespace as rows in data warehouses.

This unification of batches and streams echoes a similar call in computational theory by Eberbach. Turing computation is built around batches. Data is available in complete form at input on the Turing machine tape, then the program runs, and if it terminates, a complete output is available on the same tape. The theory of computability and complexity are built around this same encapsulated box of space and time. Much of what computers do in 2018 is actually continual computation – the reacting to events or processing streams of data that have no semantically tied termination point. That is, though the process may terminate, that isn’t particularly relevant to any analysis of computational complexity or performance we want to do. When editing a document on a computer, you care about the responsiveness keystroke to keystroke, not the entire time editing the document as if it were one giant text batch.
By contrast, modern computing systems process infinite streams of dynamically generated input requests. They are expected to continue computing indefinitely without halting. Finally, their behavior is history-dependent, with the output determined both by the current input and the system’s computation history.
– Eberbach, Goldin and Wegner – Turing’s Ideas and Models of Computation
Streams are a computational model of continuation, and therefore infinity. In their wide-ranging 2004 paper, Eberbach and friends go on to argue for models of Super-Turing computation. This includes alternative theoretical models such as the π-calculus and the $-calculus, new programming languages, and hardware architectures.
We conjecture that a single computer based on a parallel architecture is the wrong approach altogether. The emerging field of network computing, where many autonomous small processes (or sensors) form a self-configured network that acts as a single distributed computing entity, has the promise of delivering what earlier supercomputers could not.
– Eberbach et al, ibid.
These systems are now coming into existence. Through co-ordination with distributed registries (Zookeeper here), and with the improved deployment and configuration baseline devops techs have brought in, spinning up new nodes or failing over existing nodes is autonomously self-configured. Complete autonomy isn’t there, but it seems a high and not particularly desirable bar for many systems. Distributed systems and streams predate Apache Kafka, nor shall it be the last one. Yet is marks a moment where separate solutions for managing streams, tables and failover are concretized in a single technical object, a toolbox for the streaming infrastructure of infinity.

—
References
CCRU – Ccru Writings 1997-2003
Cremin – Exploring Videogames with Deleuze and Guattari: Towards an affective theory of form
Deleuze and Guattari – Anti-Oedipus
Deleuze and Guattari – A Thousand Plateaus
Eberbach, Goldin and Wegner – Turing’s Ideas and Models of Computation
Kafka, Hofman trans. – Amerika (The Man Who Disappeared)
Kreps, Narkhede and Rao – Kafka – A Distributed Messaging System For Log Processing
Kreps – Apache Kafka and the Next 700 Stream Processing Systems (talk)
https://youtu.be/9RMOc0SwRro
Narkhede – Apache Kafka Goes 1.0 https://www.confluent.io/blog/apache-kafka-goes-1-0/
Pajitnov – Tetris (game)
Stopford – The Data Dichotomy: Rethinking the Way We Treat Data and Services https://www.confluent.io/blog/data-dichotomy-rethinking-the-way-we-treat-data-and-services/
Thereska – Unifying Stream Processing and Interactive Queries in Apache Kafka https://www.confluent.io/blog/unifying-stream-processing-and-interactive-queries-in-apache-kafka/

{kind=link}